- Aug 15, 2019
- 3 min read
Updated: Nov 18, 2022

Elasticsearch-hadoop connector allows Spark-elasticsearch integration in Scala and Java language. Elasticsearch-hadoop library helps Apache Spark to integrate with Elasticsearch.
Contents:
Write JSON data to Elasticsearch using Spark dataframe
Write CSV file to Elasticsearch using Spark dataframe
I am using Elasticsearch version [7.3.0], Spark [2.3.1] and Scala [2.11].
Download Jar
In order to execute Spark with Elasticsearch, you need to download proper version of spark-elasticsearch jar file and add it to Spark's classpath. If you are running Spark in local mode it will be added to just one machine but if you are running in cluster, you need to add it per-node.
I assume you have already installed Elasticsearch, if not please follow these for installation steps (Linux | Mac users). Elasticsearch installation is very easy and it will be done in few minutes. I would encourage you all to install Kibana as well.
Now, you can download complete list of hadoop library (Storm, Mapreduce, Hive and Pig as shown below) from here. I have added elasticsearch-spark-20_2.10-7.3.0.jar because I am running Elastics 7.3 version.
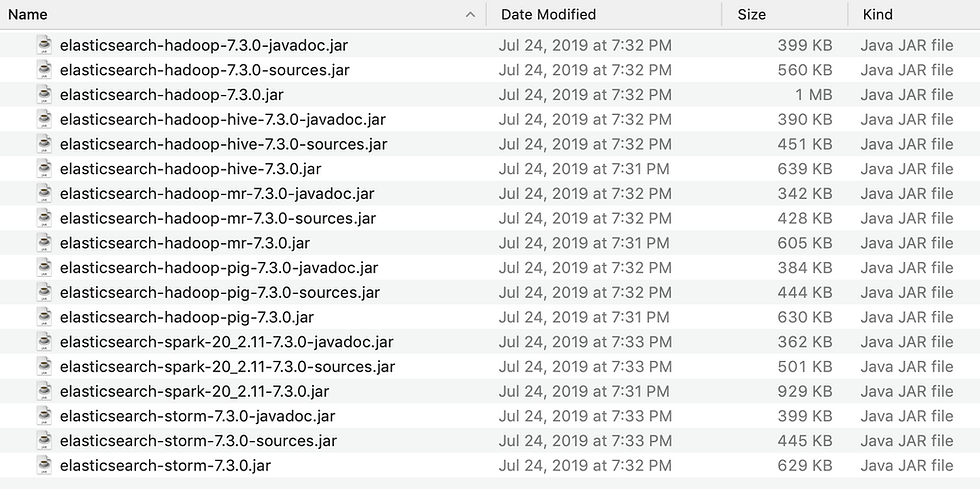
[Tip] Make sure you are downloading correct version of jar, otherwise you will get this error during execution: org.elasticsearch.hadoop.EsHadoopIllegalArgumentException: Unsupported/Unknown Elasticsearch version x.x.x
Adding Jar (Scala IDE)
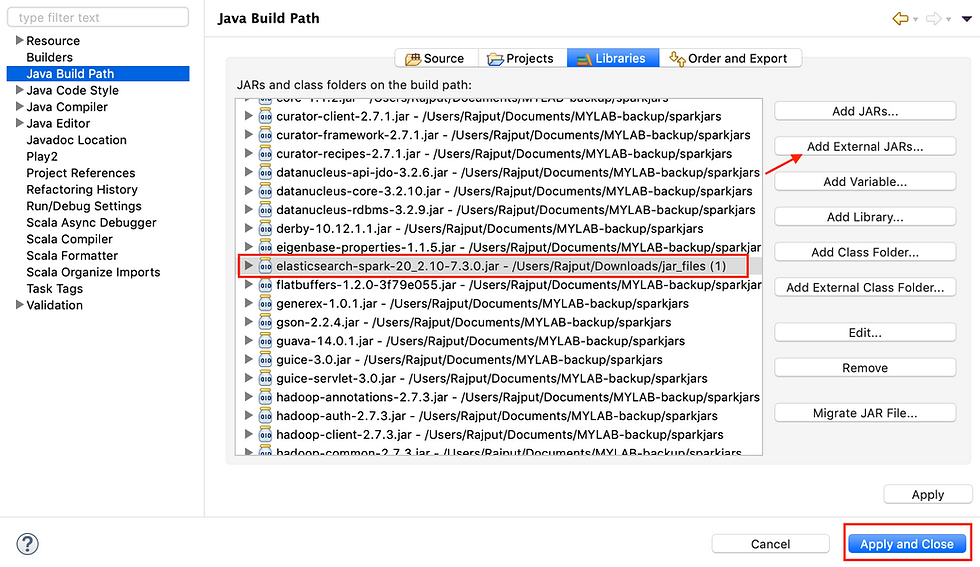
If you are using Scala IDE, just right click on project folder => go to properties => Java build path => add external jars and add the downloaded jar file. Apply and close.
Adding Jar (Spark-shell)
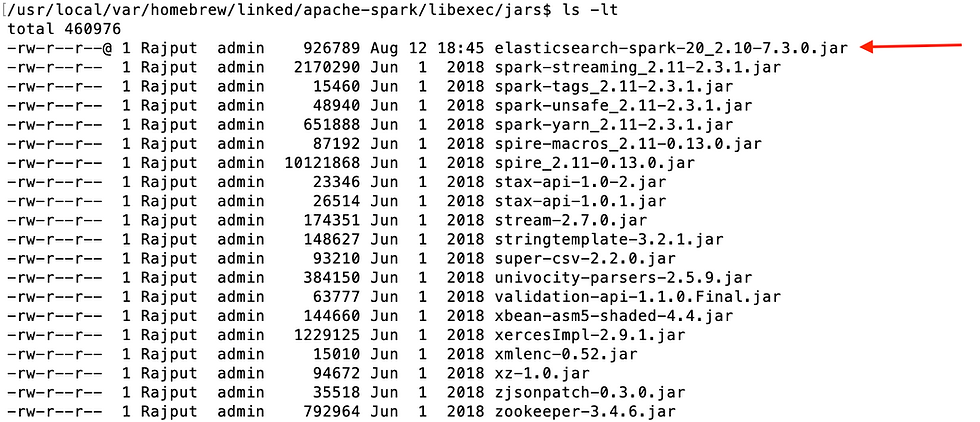
If you are using Spark-shell, just navigate to the Spark executable library where you can see all other jar files and add the downloaded jar file there. For example,
Start Elasticsearch & Kibana
Now, make sure Elasticsearch is running. If Elasticsearch is not running, Spark will not be able to make connection and you will get this error.
org.elasticsearch.hadoop.rest.EsHadoopNoNodesLeftException: Connection error (check network and/or proxy settings)- all nodes failed.
To start Elasticsearch and Kibana run this command on your terminal,
$ elasticsearch
$ kibana
Writing JSON data to Elasticsearch
In all sections these three steps are mandatory,
Import necessary elasticsearch spark library
Configure ES nodes
Configure ES port
If you are running ES on AWS just add this line to your configurations - .config("spark.es.nodes.wan.only","true")
JSON file
multilinecolors.json sample data:
[ { "color": "red", "value": "#f00" }, { "color": "green", "value": "#0f0" }, { "color": "blue", "value": "#00f" }, { "color": "cyan", "value": "#0ff" }, { "color": "magenta", "value": "#f0f" }, { "color": "yellow", "value": "#ff0" }, { "color": "black", "value": "#000" } ]
package com.dataneb.spark
import org.apache.spark.sql.SparkSession
import org.elasticsearch.spark.sql._
object toES {
def main(args: Array[String]): Unit = {
// Configuration
val spark = SparkSession
.builder()
.appName("WriteJSONToES")
.master("local[*]")
.config("spark.es.nodes","localhost")
.config("spark.es.port","9200")
.getOrCreate()
// Create dataframe
val colorsDF = spark.read.json("/Volumes/MYLAB/testdata/multilinecolors.json")
// Write to ES with index name in lower case
colorsDF.saveToEs("dataframejsonindex")
}
}
[Tip] Make sure you are writing index name in lower case otherwise you will get error:
org.elasticsearch.hadoop.EsHadoopIllegalArgumentException: Illegal write index name [ABCindex]. Write resources must be lowercase singular index names, with no illegal pattern characters except for multi-resource writes.
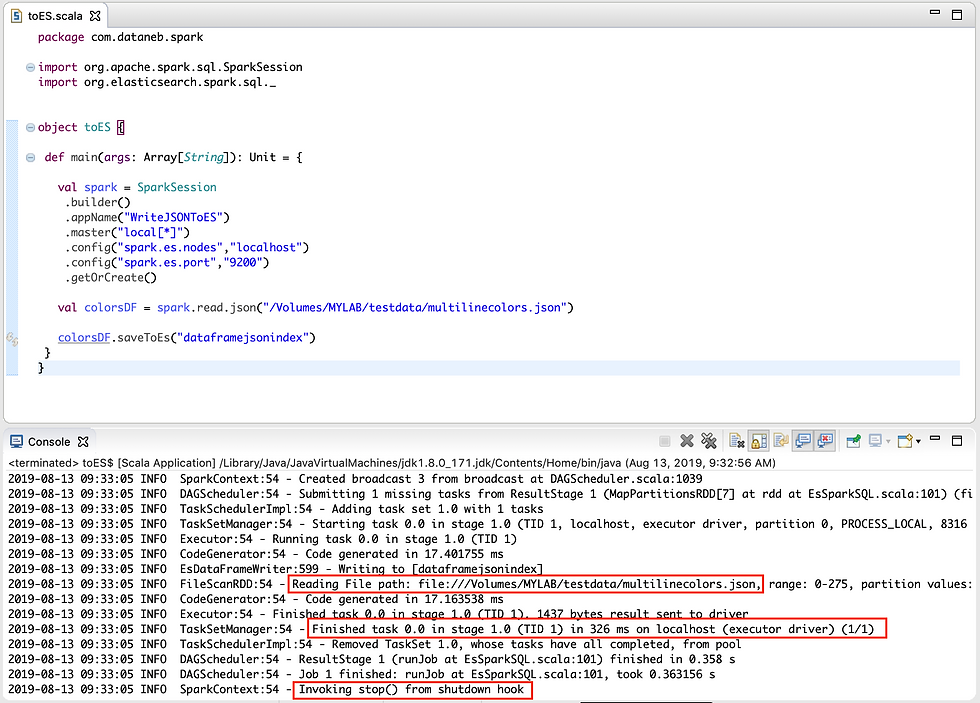
Here is the Scala IDE output,
You can also check the index created in Elasticsearch, go to Management => ES Index Management

You can further discover the index pattern in Kibana;
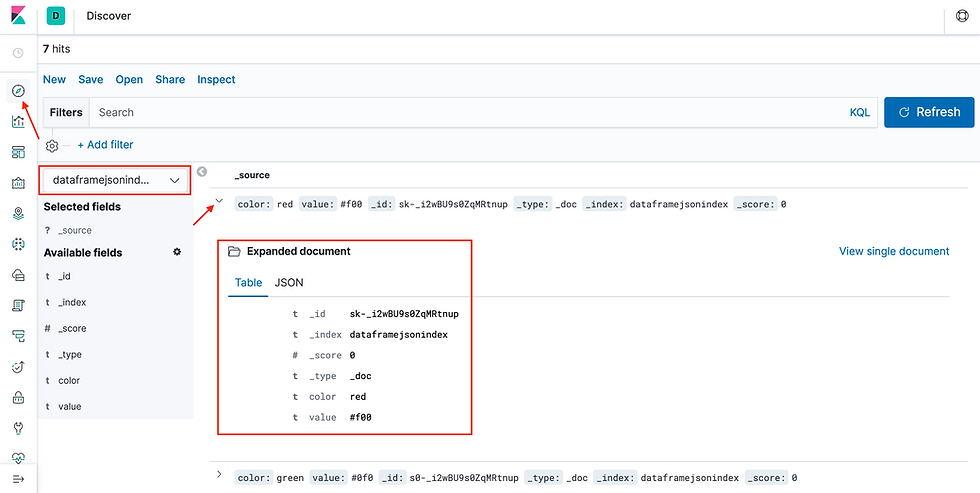
Writing CSV data to Elasticsearch
books.csv sample data:
bookID,title,authors,average_rating,isbn,isbn13,language_code,# num_pages,ratings_count,text_reviews_count
1,Harry Potter and the Half-Blood Prince (Harry Potter #6),J.K. Rowling-Mary GrandPré,4.56,0439785960,9780439785969,eng,652,1944099,26249
2,Harry Potter and the Order of the Phoenix (Harry Potter #5),J.K. Rowling-Mary GrandPré,4.49,0439358078,9780439358071,eng,870,1996446,27613
3,Harry Potter and the Sorcerer's Stone (Harry Potter #1),J.K. Rowling-Mary GrandPré,4.47,0439554934,9780439554930,eng,320,5629932,70390
4,Harry Potter and the Chamber of Secrets (Harry Potter #2),J.K. Rowling,4.41,0439554896,9780439554893,eng,352,6267,272
5,Harry Potter and the Prisoner of Azkaban (Harry Potter #3),J.K. Rowling-Mary GrandPré,4.55,043965548X,9780439655484,eng,435,2149872,33964
8,Harry Potter Boxed Set Books 1-5 (Harry Potter #1-5),J.K. Rowling-Mary GrandPré,4.78,0439682584,9780439682589,eng,2690,38872,154
Everything is same except the read method (json => csv) and index name.
package com.dataneb.spark
import org.apache.spark.sql.SparkSession
import org.elasticsearch.spark.sql._
object toES {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.appName("WriteJSONToES")
.master("local[*]")
.config("spark.es.nodes","localhost")
.config("spark.es.port","9200")
.getOrCreate()
val colorsDF = spark.read.csv("/Volumes/MYLAB/testdata/books*.csv")
colorsDF.saveToEs("dataframecsvindex")
}
}
Here is the Scala IDE output, I have two csv files books1.csv and books2.csv so you are seeing 2 task ID in result.
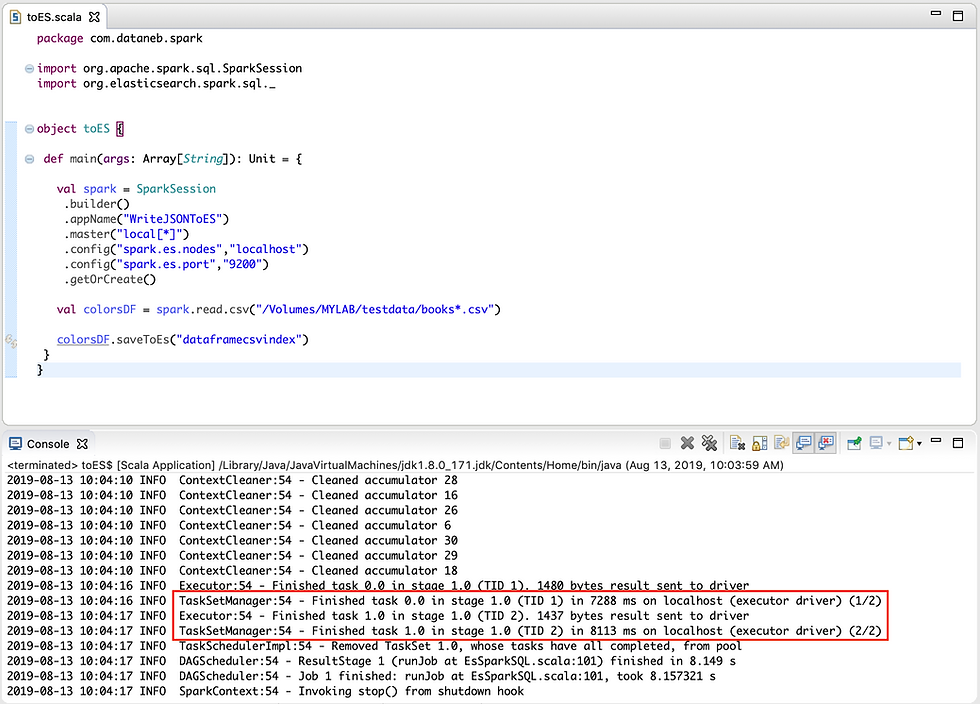
You can also check the index created in Elasticsearch, go to Management => ES Index Management

You can further create the index pattern in Kibana;
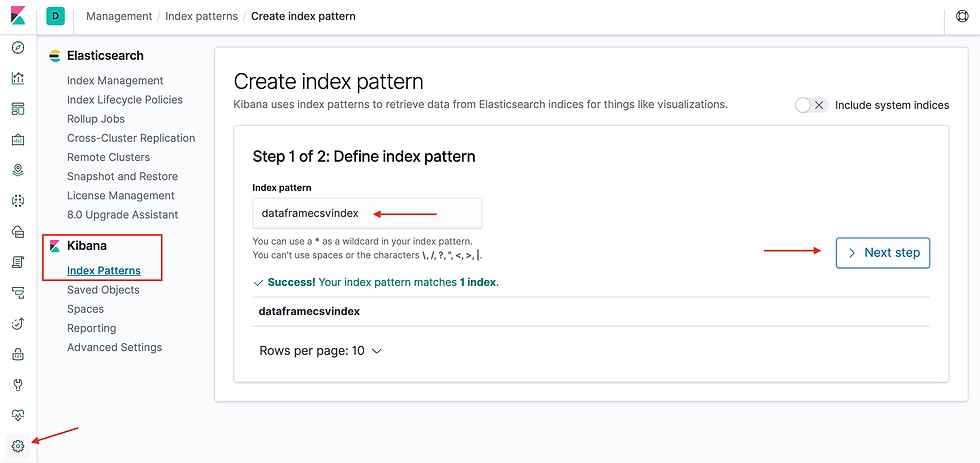
You can further discover the index pattern in Kibana. I haven't applied format options to read header while applying csv method in Spark program hence you are seeing header record in the index.
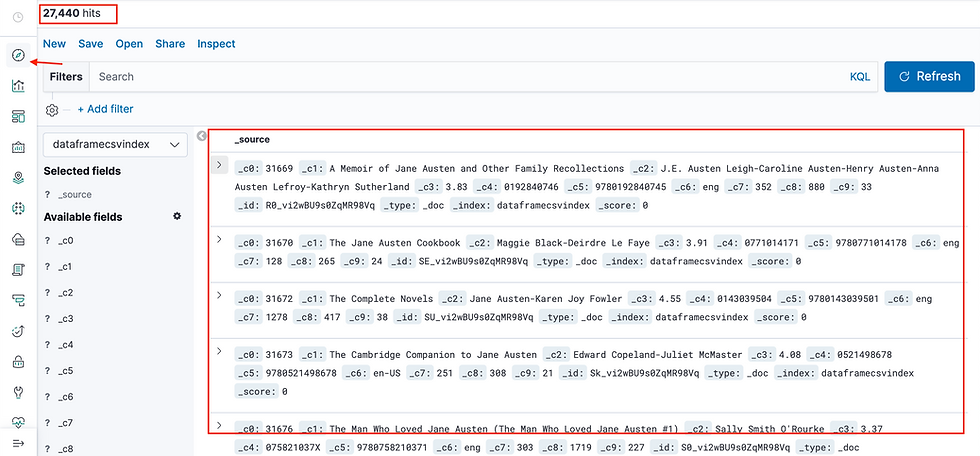
Thank you. If you have any question please write in comments section below.
_edited_edited.png)

Comments